

Introduction
Think of the early days of AI/ML like the first airplanes established a new modality for travel. The initial results were not mainstream. It took time, cost and quality improvements to scale air travel to the point that it was usable by everyone. The same is true for AI/ML. We believe that Essence® technology is a major leap forward in AI/ML. We’ve created a new AI/ML modality for computing that can be used by everyone. This blog post describes why we believe that is the case.
A Superset Approach to AI/ML
Essence, using our patented approaches (US 11373272 · Issued Jun 28, 2022, US 10846821 · Issued Nov 11, 2020, US 10037592 · Issued Jun 13, 2016) allows every application built with wantware (e.g. speak, type, drag-n-drop, ultimately any way of signaling intent) to combine and remix popular algorithms (e.g. Tensorflow, Caffe, and many others) with each other and our own generated machine instructions for parallel execution, all on the fly. This results in an artificial intelligence algorithm superset. AI/ML and traditional algorithms run together in parallel and are easily altered in real-time via natural language dialog, soon supporting compound sentences. This allows the creation of new and unique solutions to all manner of problem sets. The implications are enormous.
Essence is not about Artificial General Intelligence enabling machines to independently perform any task that a human could do. Essence is a new path towards greater augmentation of humans. The machine does not come up with its own purposes. It merely waits for humans to give it instructions. No self-aware machine or world conquering to fear here.
Viewing AI From the Lens of a New Computing Paradigm
AI has its beginnings as an academic field in 1956. It has recently become such an important technology that nations are in fierce competition to become AI Superpowers. Think of it as a kind of arms race. The winners stand to benefit in multiple ways. Hot topic areas for the field include education, autonomous vehicles, finance, commerce, security, communications, and healthcare. AI will continue to have an increasing relevance on a global scale.
Large Global Investment in AI
Price Waterhouse Coopers recently projected AI’s deployment will add $15.7 trillion to the global GDP by 2030, with China taking home $7 trillion of that total, nearly doubling North America’s $3.7 trillion in projected gains.
Despite incremental annual progressions in computing, software engineering follows a paradigm that has persisted since the 1950s. Software is mostly written by programmers. This imposes significant time, quality, and cost constraints on systems that depend upon it.
Until the paradigm changes, AI solutions are not immune from the negative effects of writing code. If the industry were to break free from that constraint, it would be reasonable to expect new AI solutions.
Our Unique Approach to AI and Everything Else in Computing
Our team believes that programming languages are insufficient for filling the gap between human intentions and machine behaviors. So we created a system that is based on a meaning representation system that we call Essence Meaning Coordinates.
Meaning Coordinates are a series (vector) of analog values defining the limits of possible meaning for any given term(s) and context(s).
Expressions of meaning and significance, mapped to Meaning Coordinates, distill an idea down into its most atomic pieces.
Here’s a sample of Meaning Coordinates: JoSmxTryChoHa
The above translates into: ‘Given a collection of events, locate the desired event within the collection and extract its contents. Then, create a new cloned event from the extracted data’.
Change the sequence of the Meaning Coordinates to change the resultant machine behaviors.
No Need to Learn Meaning Coordinates to Use Them
Meaning Coordinates supports re-expressing meaning in any language. This includes; regional variants like British or Appalachian English; completely unrelated languages like Japanese; or even fictional or hypothetical tongues like Elvish, Klingon, or a language communicated by visitors from another galaxy.
- Meaning Coordinates are remapped to any of the potential translations, including individualized slang and interpretation of ideas.
- Meaning Coordinates are re-expressed to match an individual or group’s style of expressing ideas, in real-time.
Highly compressed and permuted text as granular differences are not duplicated, but use a highly efficient hashing approach that takes up little space.
Focusing on Meaning Coordinates is the Path Towards Our Core Value Proposition
This approach sounds complicated. It is an amazingly elegant, efficient and powerful way of capturing meaning. Meaning is largely unsupported by programming languages.
We acknowledge that the answer to the coding problem is not hand-writing Meaning Coordinates. The purpose of our company is to enable anyone to create apps without writing code or Meaning Coordinates. See examples of our capabilities (Maven, Synergy, and Chameleon) that are made possible with Meaning Coordinates in video clips here.
The Essence Project – Freedom to; Imagine. Describe. Create.

History has a way of repeating itself. Especially, without the right perspective. The earth is flat, or so we thought. It would be a mistake to think that our ancestors who believed that were stupid. Some of the greatest thinkers to ever walk the planet thought that it was true.
The fact is their belief was rooted in their limited perspective. They could not observe or process the curvature of the earth as an indicator that it was not flat. They could not navigate the globe or leave the planet to gain a new perspective.
Now let’s apply that thinking to computing in arguably the most critical area, software.
The Fastest Path Mindset
Software has to be written using programming and scripting languages, or so we thought. Well, what happens when programming languages and scripting can be bypassed? Then anyone could tell any machine what they want, however they want to say it, and the machine would just do what they want it to do, safely and securely.
The Essence® Project, a nearly 8 year journey into the unknown, is about the ability to map human expression of meaning ( via natural language, text, drag-n-drop, eventually even brainwaves ) to machine behaviors in real-time. This is a powerful tool for many computing situations, including AI.
An Overview of A Superset Approach to AI/Machine Learning
I’ll warn the reader that this gets a little techie and may require a basic understanding of what AI/ML is about. Watch the video below from Spark Cognition for the AI/ML basics.

Our history of computers offers many remarkable capabilities, from numerical calculations to elaborate visualizations. We’ve often defined computers by what they do better or worse than we humans, such as better equation solving or financial recording and lesser speech synthesis or voice recognition.
As our chip technology has improved, notably from wide-vector cores ( CPU coprocessors, GPUs ) and novel architectures ( FPGAs and unique ASICs ), computers have improved on past errors and continue to approach or exceed human capabilities.
Recently, chip improvements have enabled techniques that were researched in the past but never succeeded in the market. Most of these techniques are variants on Artificial Neural Networks (ANN) as they take inputs, such as text, pictures, or sounds, and extract data to be placed into a graph of connections.
Popular examples include Recurrent Neural Networks (RNN) using a cycle of extracting data into new buffers which later feed into the same pipeline, or Convolution Neural Networks (CNN) using successive layers of signal transforms, Long Short Term Memory LSTM using feedback to earlier layers. There are many interesting variants generally providing tradeoffs that better match the subject matter.
Machines Are Not Thinking
While it is accurate to classify these approaches as ‘machine learning’ (ML), they are also often labelled ‘artificial intelligence’ which is popularly conflated with self-aware, long-term planning, and independent thought as artificial lifeforms, aka ‘Thinking Machines.’
Although the ability to recognize a dog breed accurately, translate languages, or create fake confession videos is impressive and useful, the previously mentioned approaches are still tools that follow the traditional ‘data-in, data-out’ model. The goal in clarifying this is to remind us that these are tools for humans to use instead of something that uses us.
What Makes Essence® a Different Approach to AI/ML?
The current trend of machine learning, which is mostly neural-net based, is built on layers of data transforms that expand or contract the overall amount and precision of data. Essence® technology ( implemented in every application based on it ) is a superset of this approach since it can model and *directly* use existing neural net graphs as well as classic algorithm approaches and a variety of solutions that fall in between.
We can combine and adapt on-the-fly ( no need to stop and restart to explore different combinations of algorithms, data or intent ), while auto-tuning and auto-scaling compute resources. That enables an enormous leap forward in performance speed, energy efficiency and sheer opportunities to explore possibilities at much lower cost ( no one writing the code, potentially reducing cost by up to 80% compared to legacy approaches ).
A Unified Four Part Process
We separate our approach into training, recognizing, synthesizing, and translating. In each case our capabilities capture Training, which imports/expands/labels data to understand valid examples or candidates to further classify. Recognition passes incoming data, such as text/image/sound/shape/coding-sequence, through an Essence® formula to provide new information about it, such as classify it or create new classifications. Synthesis passes data in reverse through the same formula to attempt to create a ‘valid’ example. Translation is how we alter Essence® formulas, Essence® examples, or other ML data between domains.
Example 1: Enabling Breakthroughs in Machine Vision
Problem: Consider ‘machine vision’ which can be implemented with classic edge detections and region checking or with a CNN, as Nvidia has been doing in its work on self-driving cars. There are many approaches to optimal vision, particularly considering the conditions ( only at night? only moving objects? only red balls?, etc. ), the computational-power(FLOPS)/bandwidth/wattage, and time ( do new Atoms need training? how long if so? how fast can results be made? ).
Solution: Essence technology functionally assembles transforms, permutes the operations between them to find best speeds/spaces/power-uses, and allows editing them in real-time. It generates code to; recognize objects with ML ( via CNN ), apply realtime ML training ( via FastGANN ), employs traditional heuristic ( light-scatter conjure ), while applying polynomial regression/solving ( re-sampling using quaternion log space ) approaches.
This approach allows conversion between the complicated ML models ( pill-identification, cat-breeds, voices, grammar, etc. See ‘model zoo’ or ‘kaggle examples’ ), operators( smaller transforms such as edge-detect or rescale values into a nonlinear curve), and all the connections that make the network ( how values flow from layer to layer ).
Example 2: Applied to Live Streaming of Video
Problem: The need for high quality, low latency video compression is critical to meet the growing demand for high-quality video content and other bandwidth intensive services. Increasing demands for HD and 4K and HDR streaming media negatively impacts network performance.
Solution: Our approach leverages multiple signal processing approaches ( in parallel ) to deliver paradigm-shifting performance for bandwidth-constrained OTT ( over-the-top ), OTA ( over-the-air ), cable networks and numerous remote analysis and content delivery applications.
Bandwidth Optimization
- adapts to massive drops in network connection and results by simultaneously using upsampling, prediction, de-noising, and historical frames as references.
- does not ‘see’ detail without signal data, but can provide guesses, like puzzle pieces fitting empty slots, with tolerances that might help detect anomalies or indicate warnings when data is otherwise unavailable.
- works with modern compression such as HEVC/H.265, VP9 (WebM). Also with VP10, Daala, and Cisco-Thor-Next_Gen, but the improvement of codecs only enhances the offering.
- brings a self-tuning signal-processor to mitigate compression artifacts and provide rapid adjustments to real-time or archived signal streams.
Latency Mitigation
- provides non-linear blending between previous frames and the ‘pixel-2nd-derivatives’ or ‘accelerated-directions’ to deliver most likely changes from frame to frame.
- uses the previous frames of ‘final image values’ to calculate ‘rates of change’ and then predict the likely pixels.
- Consider modern televisions that interpolate 24Hz or 30Hz cable or DVD signals and upsample them to 60Hz or 120Hz. The chip used in all known cases does linear interpolation ( mix by percentage ) between the current and previous frame. In these cases, it isn’t cost effective to provide many HD or 4K frames or memory to store all buffers for higher-quality interpolations. In this case, most incoming frames, even high-noise image frames such as the Explosions or Confetti image frames that look blocky on modern video, are using only 1/9th to 1/33rd of the original frame when translated to pattern-fields.
Prediction
- can fill in missing areas of an image. The idea of video codecs using “delta-compression” aka “don’t resend pixels if they haven’t changed or are close enough to what they just were for the past N frames” is widespread. Our approach of combining ‘delta-compression’ with known matches to use as small bit cost to replace ‘delta’ with a known example seems absent from any academic or corporate white papers.
Transformation
- allows us to alter the signal for enhanced viewing, data mining, improved recognition when matching objects, and other repurposing of the signal. If the only signal processing being done is enhancing edges to better silhouette a visual or adjusting for poor lighting conditions, then the cost is generally N operations per pixel. The cost grows quadratically as it is based on width by height for an image or more for volumetrics.
- can automatically reduce processing costs by processing at lower resolutions and resampling at higher. The bigger gains are found in cases when the processing is not ‘simple’, such as a User desire to ‘de-noise, median filter, upsample, color remap, sharpen @ 2.5X, remove unicells, and soften’.
- uses 7 techniques and for a SD video image requires 23 ‘passes’ in a standard Adobe or Autodesk pipeline, given resampling of buffers. Our approach often compress most signal processing ‘recipes’ into a single pass.
Consider the numbers, even for only handling 7X techniques:
- Standard Pipeline (Adobe-Stack/Autodesk-Pipe): SD image ops 7x read + 7x write = 14x per pixel
- Essence Pipeline ( the recipe generally fits into a single pass ): 1 read-combined-write = 1x or worst-case 2x per pixel.
- The difference here is performance, battery/watts, and efficiency for the hardware instead of bandwidth, but this ends up being a bottleneck if you need processing in real time and something takes 14 minutes instead of 1.4 minutes instead of 4.2 seconds. This example is fairly common as a test case, but could be far more extreme or far less given a user’s needs. What matters is that the end user has a choice to do these things without the overhead of an extensive pipeline.
The Transformations also include:
- Real-time compositing of objects extracted from multiple sources (e.g. files, IP locations, sensors, etc.) for product placement within live video streams
- Customization of objects per demographic or user
- Objects become transactional with a simple implementation without expensive and complex backend technologies
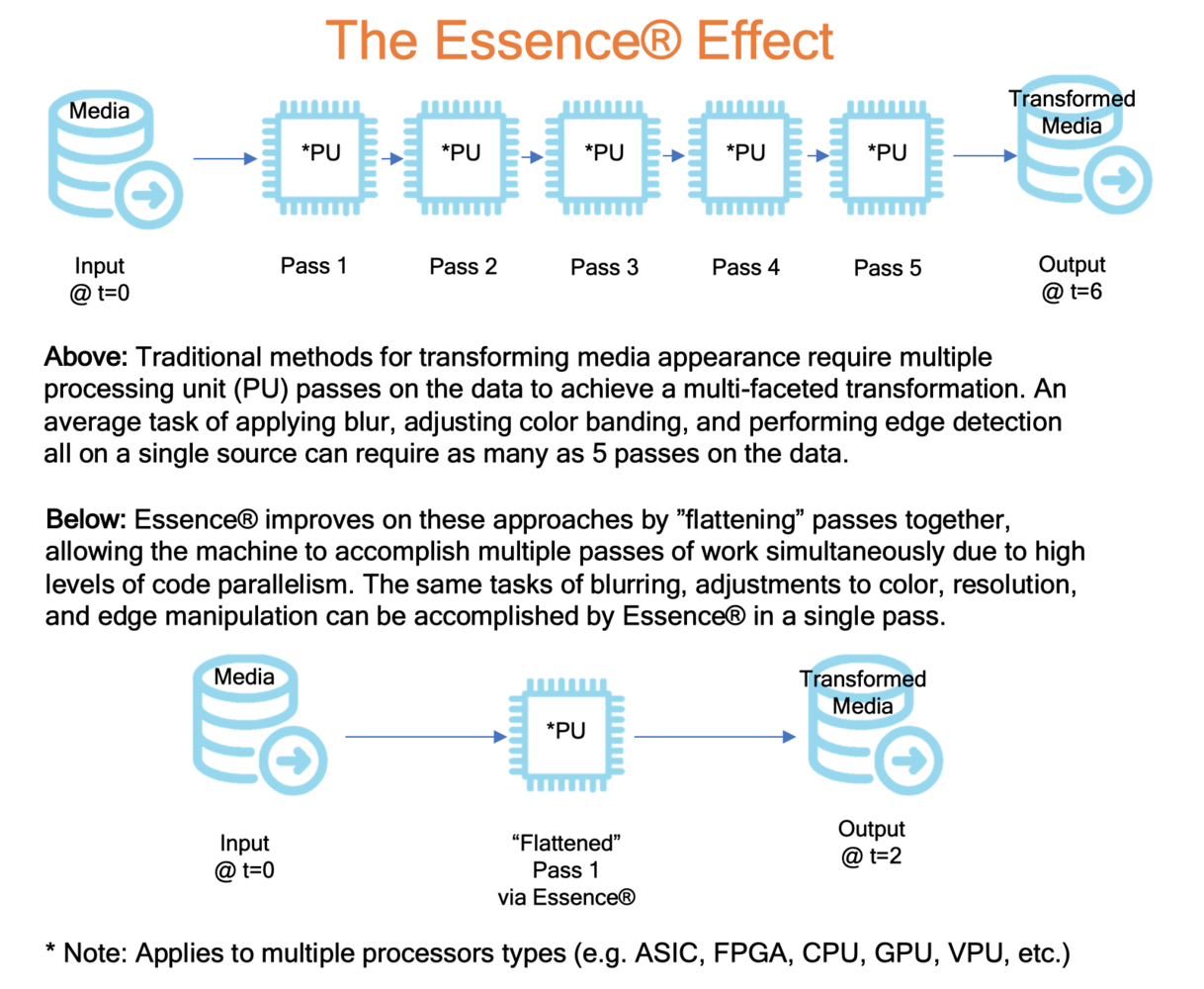
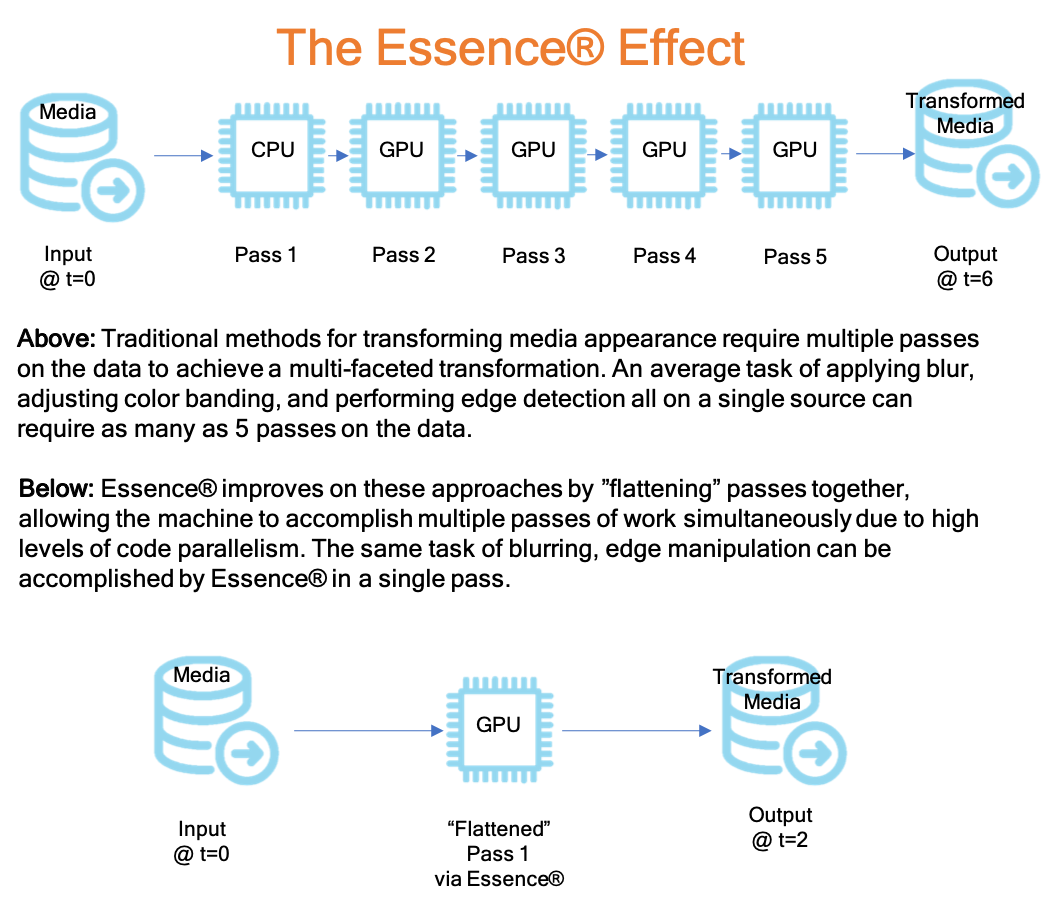
Figure 1 – The Essence® Effect
The Takeaways on AI
So the point of this article is not to say that current approaches to AI don’t work. It is that we can now bring many different approaches together, modify them, integrate and accelerate them ( with far fewer samples ). AI becomes usable at practically every feature and function level. We call this Superset AI.
The ability to transform incoming signals into easier examples changes the problem. This is particularly true for the hard to succeed corner cases such as a blurry digit for ‘eight’ that might be a ‘six’ or ‘nine’. Our approach works with user recipes for transforming one or more signals into many features at higher or lower resolutions. This makes it suited for rapidly iterating on new features or better recognized features amongst hard to classify datasets.
Note that this means we can complement existing schemas such as Berkley’s Caffe, Google’s Tensor Flow, NYC’s Torch and so on. This applies to all major distributors of learning, including Amazon, Baidu, Microsoft, and IBM. Similar to Nvidia’s Cuda Caffe, which enhances a particular recipe with faster routines. Essence can also speed up the learning or recognizing phases by iterating on the algorithms used to find machine-specific optimal combinations of instructions and bandwidth use.
At the same time, we can empower others who know nothing about coding or scripting. In most cases, the user doesn’t care about coding. The value of software is not the code, it’s the desired behaviors.
What’s Next?
As one of a series of posts, it is better to think of the series as our attempts at changing the conversion about many software engineering areas of focus. Whether it be changing the way software works in fields such as; natural language processing, machine vision, cryptography, digital currency and other transactional systems based on blockchain, or the processes associated with creating software using/not using programming languages, we intend to offer new ways to direct the conversation.
An upcoming article will focus on creating machine behaviors on-the-fly without writing code ( The Essence of Software ). In that post, we’ll address why we don’t believe that this is bad news for programmers and why programming is just a tool.
True professionals do not fall in love with their tools and stay in business. They love the outcomes. The time tested rule for business is; provide value or lose out to the competition.
At MindAptiv, we’re excited about the near future and opportunities to share our vision and our work. Follow us on our website @ https://mindaptiv.com and on social media.
We welcome the views of readers.
Get ready to ‘create at the speed of thought®‘
Ken Granville & Jake Kolb
Cofounders of MindAptiv
———————————
Notes:
- For a good overview on a popular form of ML, consider this capsule network overview: https://kndrck.co/posts/capsule_networks_explained/
- Practical and useful example everyone should be aware of with ML: http://www.labsix.org/physical-objects-that-fool-neural-nets/
- Geoff Hinton made sense but was mocked for many reasons of market/time/etc. that echo our most common dismissals. Worthy to be familiar with this angle: https://torontolife.com/tech/ai-superstars-google-facebook-apple-studied-guy/
- This post was updated on 3/7/21 to reflect a name change from Elixir to Essence Elements. This was done to avoid confusion with the Elixir Programming Language.
- This post was updated on 10/01/22 to reflect a name change from Essence Elements to Essence Atoms. This is a more accurate reflections of what our system for meaning representation is about. Links to our three foundational patents were also added.
- This post was updated on 8/25/23 to reflect a name change from Essence Atoms to Meaning Coordinates.
- For a good overview on a popular form of ML, consider this capsule network overview: https://kndrck.co/posts/capsule_networks_explained/
- Practical and useful example everyone should be aware of with ML: http://www.labsix.org/physical-objects-that-fool-neural-nets/
- Geoff Hinton made sense but was mocked for many reasons of market/time/etc. that echo our most common dismissals. Worthy to be familiar with this angle: https://torontolife.com/tech/ai-superstars-google-facebook-apple-studied-guy/
- This post was updated on 3/7/21 to reflect a name change from Elixir to Essence Elements. This was done to avoid confusion with the Elixir Programming Language.
- This post was updated on 10/01/22 to reflect a name change from Essence Elements to Essence Atoms. This is a more accurate reflections of what our system for meaning representation is about. Links to our three foundational patents were also added.
- This post was updated on 8/25/23 to reflect a name change from Essence Atoms to Meaning Coordinates.




Leave A Comment